
How we lost all user data on our Jupyter Notebook service
On Tuesday the 21st of February we did some maintenance on a Kubernetes cluster that hosts our Jupyter notebook service. This maintenance resulted in all users data that wasn’t actively being used being deleted. At the time of the maintenance this was all of our users.
In preparation for moving our Kubernetes cluster to some different hardware we needed to shrink our Kubernetes workers to allow for some more space on the underlying hypervisors. So one by one we drained and deleted a worker and then created a new smaller worker and joined it back into the cluster. This all worked smoothly and the JupyterHub service was unaffected except when we needed to move the hub process. Unfortunately you can only run one so there was about 1 minute where the web interface is down.

Once the rolling rebuild of our workers was complete we made sure the service was working as expected. All looked fine except we noticed our volumes that are attached to each user's pod were empty and freshly formatted, the lost+found directory was a few seconds old.
Now the question was why?
We suspected it was either JupyterHub itself doing something strange and reformatting disks or it was longhorn, the storage system we use to provide volumes in Kubernetes. We also run a Prometheus server in this cluster that has a volume for its data and we could tell via Grafana that all the data was still there.

Initially we suspected longhorn wasn’t the culprit and maybe JupyterHub was to blame. However we soon came across some logs from longhorn
I0221 05:32:32.608214 5485 mount_linux.go:459] Disk successfully formatted (mkfs): ext4 - /dev/longhorn/pvc-f5c0cc99-bd66-463b-801e-8a39d9adcc3c /var/lib/kubelet/plugins/kubernetes.io/csi/driver.longhorn.io/e76857eba79db5310bed1344c3a6581f12c0476b1af4ad8e6109068693ad5ee2/globalmount
This didn’t look good, Longhorn was formatting our disks, but why?
What we discovered was that the underlying data on all longhorn volumes that weren’t attached to pods wasn’t on any of our worker nodes. For all the users volumes we have a 2 replica policy meaning that the data should be on 2 out of 3 k8s worker nodes. Because we only took down one at a time this should be fine. Longhorn also blocks draining a node if this would mean there would be no healthy replicas.
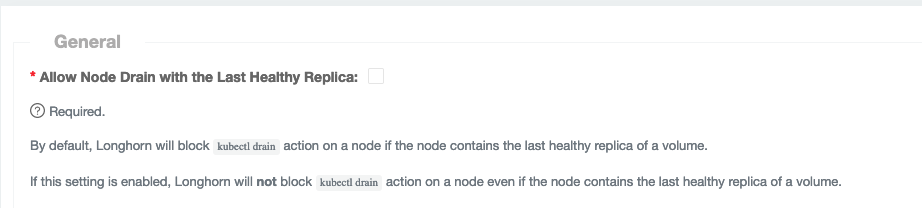
This is where the language got us. In longhorn a “healthy” replica is one that is attached, if the volume is detached then the replica is in a “stopped” state. So when we removed one k8s worker node we deleted all the data on that node. This would mean 2/3 of our volumes would only have one replica and the assumption was that this would be corrected by longhorn to recreate a replica on a different node. Draining the second node wouldn't work if there were volumes on there that only had a replica on this node right? Wrong!
We have since discovered this bug in longhorn, which essentially still counts a replica on a deleted node as fine. This looks like this has been fixed and will be in the next version of longhorn 1.4.1, we'll be sure to upgrade!
Of course a bug is really only a bug if an operator triggers it and in this case we should've checked after each worker rebuild to ensure everything was as expected. This was hampered a little with the longhorn web interface reporting that the volumes with no replicas were still consuming data.


Comments
Post a Comment